Showcase
Projects⌗
GitPorts - Typescript⌗
As I’ve mentioned previously on here, I work full time as a developer for a software studio building solutions for (primarily, though not exclusively) oil & gas companies here in Alberta. The main project my team and I work on is version controlled and source controlled using Git and GitHub. Because this project is specific to our client, the code, documentation, and issue tracking are all hosted primarily in a private GitHub repo that our development team has access to. Unfortunately, the client we’re doing work for has demanded reports detailing the issues currently active, in progress, completed, etc. as well as details such as who’s working on the issue, time frames, etc. All of which are inaccessible to our client due to the private repository. Queue GitPorts.
GitPorts is a CLI tool that allows a project manager/quality analyst/business analyst/whom-ever else might need it to quickly generate a filtered report of the issues currently open and closed in a GitHub repository. Leveraging the use of personal OAuth tokens and the GitHub REST API, GitPorts is able to generate a beautifully formatted report detailing our Github issues including who’s working on what, the current tags attached to the issue, and even the person who opened the issue. Using the built in flags, a user can filter issues based on the issue owner and the tags currently attached to the issue in GitHub (though more expansive filters are planned in the future), allowing fine-tuned reporting of issues from Github.
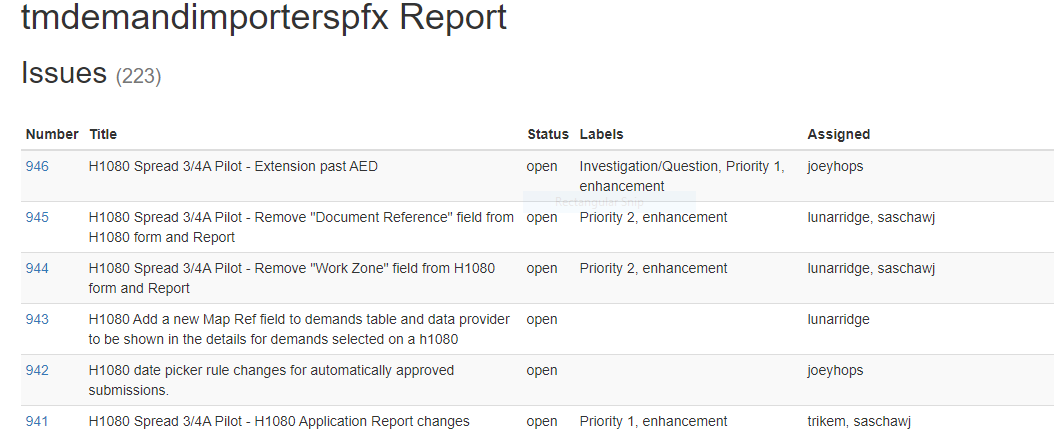
GitPorts Report Example:⌗
GitPorts-GUI - Python⌗
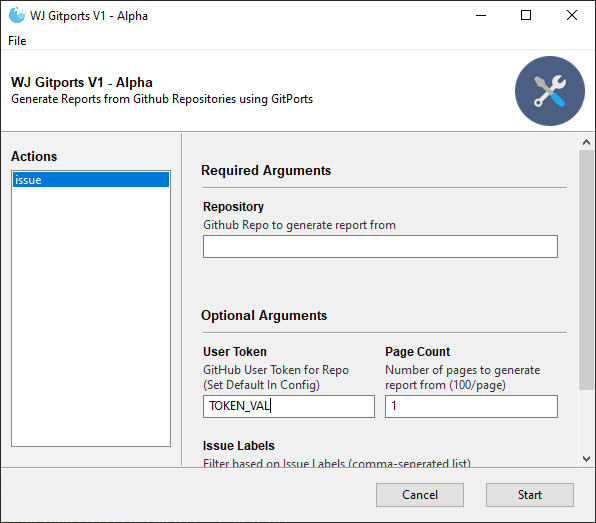
Writing a CLI tool to generate a report from GitHub is all well and good, and works rather well for the given use case, however for people with little-to-no technical/development experience (i.e. The people who actually need this tool) using a CLI tool tends to leave them feeling rather nervous. Because of this, I wanted to build something that could conceivably be used by the non-development members of my team at work, as they’re the ones who would need to generate the report regardless.
Once I had the CLI tool working to a certain standard, I began looking at ways to take the process from the command line to the desktop. Using python, I was able to leverage the ArgParser library to create what is, essentially, a simple GUI shell around the CLI application. The GUI encapsulates all variables, flags, and even setup/installation/configuration processes from the CLI, allowing the user to have a seamless GUI experience without the overhead of having to write a fully graphical implementation of GitPorts.
Since writing GitPorts & GitPorts-GUI it has become the primary issue-reporting utility for my team.
Sinix - C++, ASM⌗
For as long as I’ve been programming I’ve been interested in increasingly lower and lower level development as time has gone on. Starting with what could only be described as an incredibly naive attempt to sell a poorly made Linux Distribution as a “business” in the last year of elementary, I’ve slowly but surely replaced my Naivety with knowledge, enough so that I’ve gone ahead and created my own Toy OS to play with. Being (more or less) Unix based, I couldn’t help but call it Sinix (Sounds cooler than Cosix or Tanix) after being enamored by the trigonometric operation Sin(32) or Sin32 in High School.
Lately I haven’t had the opportunity to poke at it as much as I’d like. Not to mention the fact that I’ve slowly started falling in love with Rust. While this operating system is no where near close to being even remotely close to “finished”, it’s still neat to say “Hey, look at my Operating System, I wrote it myself.”
Haven3 - C++ (wxWidgets)⌗
This one is a beast and, frankly, a poorly designed one at that. Looking back, I was still fairly new to C++ when I started building this, mostly as a way to help me learn and practice C++. Eventually however, new features became harder and harder to implement, and I started spending less and less time working on the really “neat” features I was originally so gung-ho to implement. As of now, I haven’t pushed an update to this in a good little while, rather unfortunately because I decided to take a break. Now I can’t remember what I was implementing originally. I’ll probably start a Haven4 sooner rather than later, or possibly Raven (In Rust). Not sure though, this was still really fun to work on either way, and I’ll always be on the lookout for the next memory-efficient lightweight text editor to replace VSCode with.
Haven - C⌗
The original Haven text editor, the start of my obsession with building a Text Editor that is lightweight, provides full syntax highlighting with the ability to add new languages if required, includes a full plugin system, etc. Oh, and one that doesn’t literally eat through the entirety of my 16GB of RAM would be nice as well.
Okay, that’s an over exaggeration, but only a tad. My frustrations with modern text editors run deep. That’s why Haven was such a fascinating project to me. Coming from a Unix/Linux background with a love of the Vi(m) editor, creating a console based editor for the modern age seemed like a no-brainer. Unfortunately, as this was quite literally one of the first times I had ever written C code myself, it was inevitably a lot harder than I originally imagined. Which is why I eventually created the various offshoots, Haven2 (unpublished), and eventually Haven3 which bears absolutely no resemblance to either Haven or Haven2. Funny how that happens eh?
Bunder - Javascript (CLI)⌗
This is an interesting one for sure. As I’m sure you can tell by now, I’m absolutely fascinated with the way software works more than anything else. On Windows this is simple, at least, on the surface it’s simple. Download an installer, perhaps having to make the distinction between your architecture, and run it. That’s basically the entire Windows software experience. But if you’re a nerd like me then the far more interesting Software installation experience would be on Linux. Since Linux has no universal binary structure (or means of managing shared libraries for that matter) installing Linux software is usually significantly more complicated than installing software on Windows.
Because of this, I wanted to take a crack at implementing my own Package Management Framework. I succeeded somewhat in creating a Source-based Linux package management framework that, more or less, managed the tracking of software installations and dependencies through the use of directories. Why I decided to write this in Javascript of all languages, well, your guess is as good as mine.
If I had to implement it again, which I might you never know, I’d probably make a significant number of changes to the architecture of the framework. For instance, while writing a source based Package Management Framework is a lot easier than implementing the creation and installation of binary packages, I personally believe that that would be the last hill to climb before Linux eats the Desktop world. So I’d probably want binary files, I’d definitely implement it in a different language too.
Professional Work⌗
As a professional software engineer, I’d be remiss if I didn’t share some of the professional work I’ve done as well. Unfortunately, as these projects are indeed proprietary I cannot provide the code for them.
PALMS - Sharepoint, Typescript, React⌗
For Trans Mountain
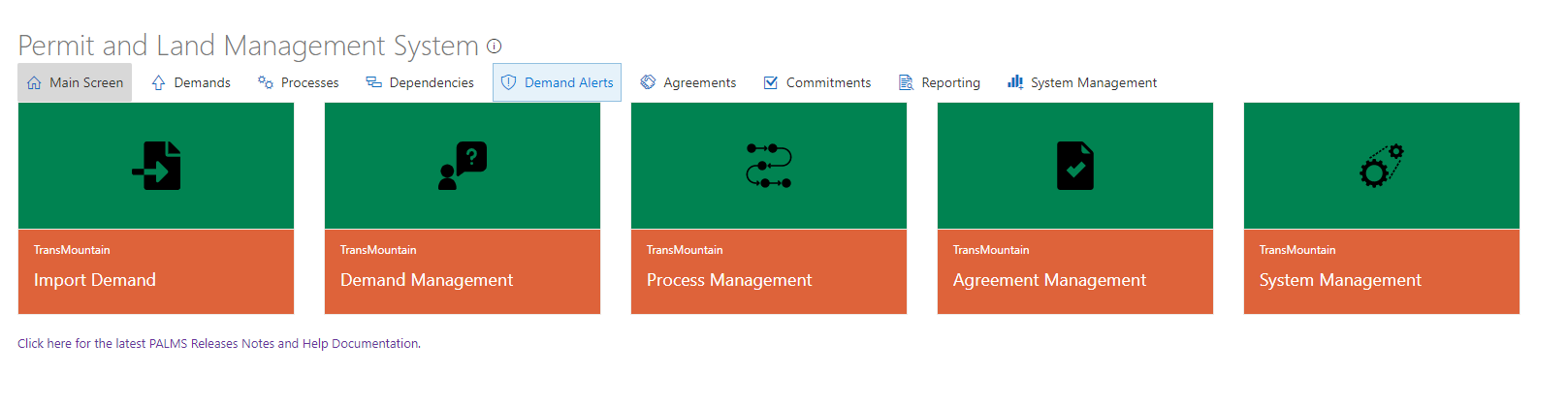
Easily the biggest project I’ve ever worked on, professionally or otherwise. What started as a relatively standard Sharepoint Migration project for TM rapidly turned into us building what would, very very quickly become the source of truth for just about all the Compliance data within Trans Mountain. Written as a modern Sharepoint Webpart in React and Typescript, we basically turn Sharepoint into a bloated DAL, allowing us to run complex operations and algorithms in order to generate reports, data, and compliance audits required for the Construction of the Pipeline. While I can’t take credit for writing the entirety of this system, I can take credit for writing 1/3 of it!
RewardBank - Javascript, React, Redux, PostgreSQL⌗
Former Project Lead

RewardBank is a subsidiary of RMG (Retail Media Group) that acts primarily as an AirMiles/LoyaltyOne Brokerage platform, allowing small-scale business owners to purchase and manage orders and transactions for AirMiles reward miles. Because LoyaltyOne refuses to work with customers under a certain size, RMG purchases large amounts of AirMiles and then sells those to smaller customers than would usually have the opportunity to use AirMiles at their business if they had gone directly through LoyaltyOne.
The RewardBank project itself was a doozy for sure, written in just over a year by two colleagues of mine, and ported from a custom solution built on an Ancient ruby web framework known as Ruby Ramaze, the project was simultaneously utterly incredible in it’s design, and also horribly flawed.
My biggest claim to fame on this project, despite having implemented countless features and bugfixes, is the time I managed to find and remedy a massive memory leak that had been causing Gigabyte large jumps in memory throughout the applications lifecycle. I spent three days in my office glued to the computer screen, staring at heat maps and call hierarchies pixel by pixel to track down what was causing the leak. Ultimately I managed to implement a fix (which was, unfortunately, only a few dozen lines or so) that cut the processes memory in half, allowing the server to stay on longer without needed to be turned over.